1장 데이터 분석 개요
1절 데이터 분석 기법의 이해
1. 데이터 처리
가. 개요
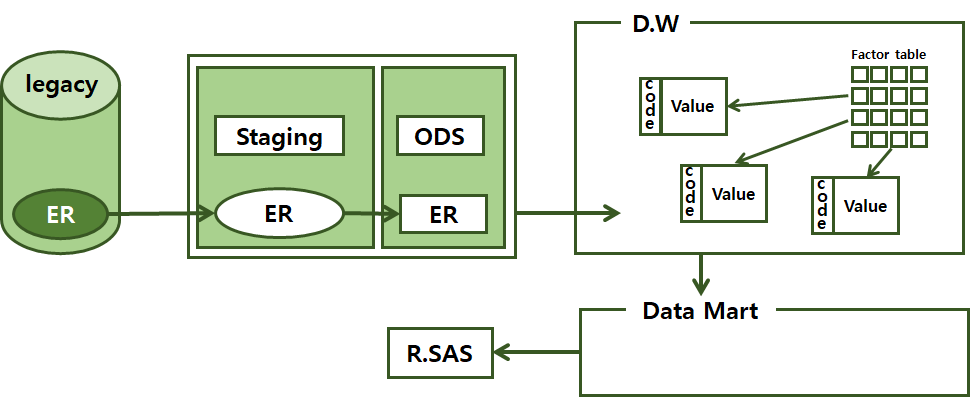
나. 활용
· 데이터 웨어하우스(DW)와 데이터 마트(DM)를 통해 분석 데이터를 가져옴
· 기존 운영시스템(Legacy)이나 스테이징 영역(Staging area)과 ODS(Operational Data Store)에서 데이터를 가져옴
· 가급적이면 클린징 영역인 ODS에서 데이터 전처리를 해서 DW나 DM 결합하여 활용하는 것이 가장 이상적
다. 최종 데이터 구조로 가공
1) 데이터마이닝 분류
· 분류값과 입력변수들을 연관시켜 인구통계, 요약변수, 파생변수 등을 산출
2) 정형화된 패턴 처리
가) 비정형 데이터
· DBMS에 저장됬다가 텍스트 마이닝을 거쳐 데이터마트와 통합
나) 관계형 데이터
· DBMS에 저장되어 사회 신경망 분석을 거쳐 데이터 마트와 통합
2. 시각화(시각화 그래프)
· 시각화는 가장 낮은 수준의 분석이지만 잘 사용하면 복잡한 분석보다도 더 효율적
· 빅데이터 분석, 탐색적 분석에서 시각화는 필수
· SNA 분석(사회연결망 분석) 자주 활용
3. 공간분석(GIS)
· 관련된 속성들을 시각화
· 크기, 모양, 선 굵기 등으로 구분
4. 탐색적 자료 분석 (EDA)
가. 개요
· 특이한 점이나 의미 있는 사실을 도출하고 분석의 최종 목적을 달성해가는 과정
· 구조적 관계를 알아내기 위한 기법
나. EDA의 4가지 주제
· 저항성의 강조, 잔차 계산, 자료변수의 재표현, 그래프를 통한 현시성
5. 통계분석
가. 통계
· 어떤 현상을 종합적으로 한눈에 알아보기 쉽게 일정한 체계에 따라 숫자와 표, 그림의 형태로 나타내는 것
나. 기술통계(descriptive statistics)
· 표본이 가지고 있는 정보를 쉽게 파악
다. 추측(추론)통계(inferential statistics)
· 표본의 표본 통계량으로부터 모집단 특성인 모수에 관해 통계적으로 추론
6. 데이터 마이닝
가. 개요
· 대용량 자료로 부터 관계, 패턴 규칙 등을 탐색하고 유용한 지식을 추출
나. 방법론
· 데이베이스에서의 지식 탐색
· 기계학습(machine learning) : 인공신경망, 의사결정나무, 클러스터링, 베이지안분류, SVM 등
· 패턴인식(pattern recognition) : 장바구니 분석, 연관규칙 등
2장 R 프로그래밍 기초
1절 R소개
1. 데이터 분석 도구 현황
가. R의 탄생
· R은 오픈소스 프로그램으로 통계 · 데이터마이닝과 그래프를 위한 언어
· 다양한 최신 통계분석과 마이닝 기능을 제공
· 세계적으로 많은 사용자들이 다양한 예제를 공유
· 다양한 기능을 지원하는 많은 패키지가 수시로 업데이트
나. 분석도구 비교
| SAS | SPSS | 오픈소스 R | |
| 프로그램 비용 | 유료, 고가 | 유료, 고가 | 오픈소스, 무료 |
| 설치용량 | 대용량 | 대용량 | 모듈화로 간단 |
| 다양한 모듈 지원 및 비용 | 별도구매 | 별도구매 | 오픈소스 |
| 최근 알고리즘 및 기술 반영 | 느림 | 다소느림 | 매우빠름 |
| 학습자료 입수의 편의성 | 유료 도서 위주 | 유료 도서 위주 | 공개논문 및 자료 많음 |
| 질의를 위한 공개 커뮤니티 | NA | NA | 매우 활발 |
| 유지보수 | 쉽다 | 쉽다 | 어렵다 |
다. R의 특징
1) 오픈소스 프로그램
2) 그래픽 및 성능
3) 시스템 데이터 저장방식
4) 모든 운영체제
5) 표준 플랫폼
· S 통계 언어를 기반으로 구현
· R/S 플랫폼은 통계 전문가들의 사실상의 표준 플랫폼
6) 객체지향언어이며 함수형 언어
나) 함수형 언어 특징
· 더욱 깔끔하고 단축된 코드
· 매우 빠른 코드 수행 속도
· 단순한 코드로 디버깅 노력 감소
· 병렬 프로그래밍으로의 전환이 더욱 용이
2절 R 기초 - 1
1. 통계 패키지 R
1) 패키지(Package)
· install.package("AID")
· install.package("AID","C\Apps\R")
2)프로그램 파일 실행
| 기능 | R코드 | 비고 | ||
| 스크립트로 프로그래밍 된 파일 실행하기 | source("파일명") | 오른쪽 방향키 | ||
| 프로그램 파일 | sink(file,append,split) 함수 : R코드 실행결과를 특정 파일에서 출력 | split : 출력파일에만 출력하거나 콘솔창에 출력(디폴트 값(FALSE)는 파일에만 실행 결과 출력) | ||
| pdf() 함수 : 그래픽 출력을 pdf 파일로 지정 | 예시 : pdf("a_out.pdf"), pdf("d:\ljw-study\R\a_out.pdf") | |||
| dev.off()로 파일 닫기 | ||||
2절 R 기초 - 2
1. R 기초중에 기초
| 기능 | R코드 | 비고 |
| 출력하기 | 복합적 데이터 구조(행렬, list 등)를 출력할 수 없음 | 예시) print(a), cat("a","b","c") |
(대입연산자) | <-, <<-, =, -> | |
| 변수 목록보기 | ls(), ls.str() | |
| 변수 삭제하기 | rm() | rm(list=ls()) : 모든 변수를 삭제할 때 사용 |
| 벡터 생성하기 | c() | 벡터의 원소 중 하나라도 문자가 있으면 모든 원소의 모드는 문자형태로 변환 됨 |
| R 함수 정의하기 | function(매개변수1,매개변수2,,,,,배개변수n){expr 1,expr 2,...,expr m} | 전역변수 : <<-를 사용하여 전역변수로 지정할 수 있지만 추천 하지 않음 |
+ #R 기초 데이터핸들링
+ bb<-c("a","b","c")
> bb[2]
[1] "b"
> bb[c(1,2)]
[1] "a" "b"
> #for문
> x<-c()
> for(i in 1:9)
+ {
+ x[i]=i*i
+ }
> x
[1] 1 4 9 16 25 36 49 64 81
> #while문
> i=1
> while(i<10)
+ {
+ i =i+1
+ print(i)
+ }
[1] 2
[1] 3
[1] 4
[1] 5
[1] 6
[1] 7
[1] 8
[1] 9
[1] 10
> #조건문 if~else if문
> #조건을 판단하는 연산자
> # == 같다, != 같지 않다, >=크거나 같다, >크다, <작다, <= 작거나같다
> x<-c(1,2,3,4,5)
> x
[1] 1 2 3 4 5
> y<-x+5
> y
[1] 6 7 8 9 10
> if(sum(x)<sum(y)) {print(y); print(mean(x))}
[1] 6 7 8 9 10
[1] 3
> if(sum(x)>sum(y))
+ {
+ print(x)
+ }else{
+ print("조건에 맞지 않습니다.")
+ }
[1] "조건에 맞지 않습니다."
> # ifelse문
> # ifelse(조건문,TRUE일때실행구문, FALSE일때 실행 구문)
> ifelse(mean(x)>mean(y),"x의 평균이 y의 평균보다 큽니다.","x의 평균이 y의 평균보다크지 않습니다.")
[1] "x의 평균이 y의 평균보다크지 않습니다."
> #사용자 정의 함수
> # Fucntion 키워드를 이용해서 함수를정의할수 있다.
> # 인수를 이용한 함수,인수없는 함수를 만들 수 있다.
> func1<-function(param)
+ {
+ isum<-0
+ for(i in 1:param){
+
+ isum=isum+i
+ }
+ print(isum)
+ }
> #함수 호출
> func1(4)
[1] 10
2. R 프로그램 소개
| 기능 | R코드 | 비고 |
| 데이터 할당 | a<-1, a=1 | |
| 화면 프린트 | a, print(a) | |
| 결합 | x<-c(x,y,z) | C함수는 문자, 숫자, 논리값, 변수를 모두 결합 가능하며 벡터와 데이터셋을 생성 가능 |
| 수열 | seq(from=0, to=20, length.out=5) | 콜론(:), seq 함수를 사용하여 시작값에 최종값까지의 연속적인 숫자 생성, seq 함수는 간격과 결과값의 길이를 제한 가능 |
| 반복 | rep(1:4, each=2),rep(c,each=2) | rep 함수는 숫자나 변수의 값들을 time 인자에 지정한 횟수만큼 반복 |
| 문자 붙이기 | paste(A, c("e","f")), paste(A,10,sep="") | paste 함수는 문자열을 seq인자에 지정한 구분자로 연결시켜 줌 |
| 문자열 추출 | substr("Bigdataanalysis",1,4) | substr(문자열, 시작점, 끝점) 함수는 문자열의 특정부분을 추출 가능 |
| 논리값 | a<-True, a<-T, b<-False, b<-F | T도 True로 인식 |
| 논리연산자 | 크다, 크거나 작다 : >, >= | |
| 벡터의 원소 선택하기 | V[-n] : 제외하고자 하는 자리수 | n은 원소의 자리수, V는 벡터 이름 |
> #수열생성
> 10:30
[1] 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
> 30:10
[1] 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10
> 5:-5
[1] 5 4 3 2 1 0 -1 -2 -3 -4 -5
> rep(1,5)
[1] 1 1 1 1 1
> rep(100,10)
[1] 100 100 100 100 100 100 100 100 100 100
> #times 인자 :앞에 나온 숫자를 몇번 반복할지를 정하는 인자
> rep(c(10,20),times=2)
[1] 10 20 10 20
> #each 인자 : 앞에 나온 숫자 각각을 몇번 반복할지를 정하는 인자
> rep(c(1,3),each=2)
[1] 1 1 3 3
> rep(c("aaaaa","bbbbb"),times=3) #숫자 뿐만 아니라 문자열도 반복 가능하다.
[1] "aaaaa" "bbbbb" "aaaaa" "bbbbb" "aaaaa" "bbbbb"
> seq(2,10) #시작 숫자와 끝숫자를 정해주면 1씩 증가시켜서 수열을 만든다.
[1] 2 3 4 5 6 7 8 9 10
> seq(from=3, to=10)
[1] 3 4 5 6 7 8 9 10
> seq(from=2,to=10,by=2)
[1] 2 4 6 8 10
> seq(from=2,to=10,length.out=4)
[1] 2.000000 4.666667 7.333333 10.000000
> seq(from=1,by=2,length.out=10)
[1] 1 3 5 7 9 11 13 15 17 19
> seq(from=1,to=10,length.out=3)
[1] 1.0 5.5 10.0
> seq(from=1,to=10,length=3)
[1] 1.0 5.5 10.0
> seq(from=2,to=10,length=3)
[1] 2 6 103. 벡터의 연산
| 연산자 우선순위 | 뜻 | 표현방법 |
| [ [[ | 인덱스 | a[1] |
| $ | 요소 뽑아내기, 슬롯 뽑아내기 | a$coef |
| ^ | 지수 | 5^2 |
| - + | 단항 마이너스 플러스 부호 | -3, +5 |
| : | 수열 생성 | 1:10 |
| %any% | 특수 연산자 | %/% 나눗셈 몫, %% 나눗셈 나머지, %*% 행렬의 곱 |
| * / | 곱하기, 나누기 | 3*5, 3/5 |
| + - | 더하기, 빼기 | 3+5 |
| == != <> <= >= | 비교 | 3==5 |
| ! | 논리 부정 | !(3==5) |
| & | 논리 "and", 단축(short-circuit) "and" | TRUE&TRUE |
| | | 논리 "or", 단축(short-circuit) "or" | TRUE|TRUE |
| ~ | 식(formula) | lm(log(brain)~log(body),data=Animals) |
| -> ->> | 오른쪽 대입 | 3->a |
| = | 대입(오른쪽을 왼쪽으로) | a=3 |
| <- <<- | 대입(오른쪽을 왼쪽으로) | a<3 |
| ? | 도움말 | ?lm |
4.벡터의 기초통계
| 기능 | R코드 | 비고 |
| 평균 | mean(변수) | 변수의 평균 산출 |
| 합계 | sum(변수) | 변수의 합계 산출 |
| 중앙값 | median(변수) | 변수의 중앙값 산출 |
| 로그 | log(변수) | 변수의 로그랎 산출 |
| 표준편차 | sd(변수) | 변수의 표준편차 산출 |
| 분산 | var(변수) | 변수의 분산 산출 |
| 공분산 | cov(변수1, 변수2) | 변수간 공분산 산출 |
| 상관계수 | cor(변수1, 변수2) | 변수간 상관계수 산출 |
| 변수의 길이 값 | length(변수) | 변수간 길이를 값으로 출력 |
3절 입력과 출력
| 기능 | R 코드 | 비고 | |
데이터를 입력 | 편집하고 데이터 프레임에 덮어 씌우기 | ||
자리수 정의 | options(digits=num) | 예)3.141593, 314.1593 | |
| 파일에 출력하기 | sink() | ||
| 파일 목록 보기 | list.files(recursive=T, all.files=T) | ||
해결하기 | R에서는 c:datasample.txt로 인식 | c:\\data\\sample.txt | |
읽기 | ("파일이름", widths=c(w1,w2,···,wn) | ||
(변수 구분자 포함) | ("파일이름", sep="구분자") | (해결 3) read.table("파일이름", sep="구분자", header=T) | |
(변수 구분자는 쉼표) | ("파일이름",header=T) | (해결 1) read.csv("파일이름", header=T, as.is=T) | |
| CSV 데이터 파일로 추력(변수, 구분자는 쉼표) | (행렬 또는 데이터프레임,"파일이름",row.names=F) | (해결 2) write.csv(dfm,"파일이름",row.names=F) | |
(변수 구분자는 쉼표) | read.table("http://www.example.com/download/data/data.txt") | what=logical(0) 토큰을 논리값으로 해석 | |
테이블 읽어 올때 | t<-readHTMLTable(url) | ||
(웹 테이블) 읽기 | token<-scan("a.txt", what=list (v1=character(0), v2=numeric(0), n=num, nlines=num, skip=num, na.strings=list) | ||
* 외부데이터 불러오기
· read.csv() 함수로 csv 불러오기
- 라벨 구분이 ,(콤마)인 경우에 사용하기 간편
- 라벨 구분이 tab으로 구분된 파일이라면 sep="\t" 옵션 사용
· read.table 일반 텍스트 형태의 파일을 읽어서 데이터 프레임 담기
- read.table 데이터를 R로 불러들이고 데이터 프레임에 담기
> #setwd()함수를 이용해서 작업디렉토리를 지정
> setwd("C:\\ljw-study\\R")
> x<-read.csv("aa.csv")
> x
id name score
1 1 홍길동 88
2 2 김말똥 90
3 3 박길동 100
> y<-read.csv("bb.csv")
> y
X1 홍길동 X88
1 2 김말똥 90
2 3 박길동 100
> y<-read.csv("bb.csv",header=FALSE)
> y
V1 V2 V3
1 1 홍길동 88
2 2 김말똥 90
3 3 박길동 100
> names(y)<-c("id","name","score")
> y
id name score
1 1 홍길동 88
2 2 김말똥 90
3 3 박길동 100
> # ROW 맨앞에 1 2 3 Row Index제거
> write.csv(y,"cc.csv",row.names=FALSE)
> y<-read.csv("cc.csv")
> y
id name score
1 1 홍길동 88
2 2 김말똥 90
3 3 박길동 100
> txt<-read.table("houses.txt")
> txt
V1 V2 V3 V4 V5 V6
1 Price Floor Area Rooms Age Cent.heat
2 52.00 111.0 830 5 6.2 no
3 54.75 128.0 710 5 7.5 no
4 57.50 101.0 1000 5 4.2 no
5 57.50 131.0 690 6 8.8 no
6 59.75 93.0 900 5 1.9 yes
> txt<-read.table("houses.txt",header=T)
Error in if (header) { : argument is not interpretable as logical
추가정보: 경고메시지(들):
1: In Ops.factor(left) : ‘!’ not meaningful for factors
2: In if (!header) rlabp <- FALSE :
length > 1 이라는 조건이 있고, 첫번째 요소만이 사용될 것입니다
3: In if (header) { :
length > 1 이라는 조건이 있고, 첫번째 요소만이 사용될 것입니다
> txt
V1 V2 V3 V4 V5 V6
1 Price Floor Area Rooms Age Cent.heat
2 52.00 111.0 830 5 6.2 no
3 54.75 128.0 710 5 7.5 no
4 57.50 101.0 1000 5 4.2 no
5 57.50 131.0 690 6 8.8 no
6 59.75 93.0 900 5 1.9 yes4절 데이터 구조와 데이터 프레임 - 1
1. 벡터(Vector)
가. 벡터들은 동질적이다.
나. 벡터의 위치로 인덱스 된다.
다. 벡터는 인덱스릉 통해 여러개의 원소로 구성된 하위 벡터를 반환할 수 있다.
라. 벡터 원소들은 이름을 가질 수 있다.
> #벡터
> c(1,2,3,4)
[1] 1 2 3 4
> c('a','b','c')
[1] "a" "b" "c"
> vector1<-c(11,22,33) #대입연산자
> vector1
[1] 11 22 33
> vector2=c(21,22,11) #대입 연산자
> vector2
[1] 21 22 11
> vector2[2]
[1] 22
> vector2[1]
[1] 21
> aa<-c(33,44,55,66,77)
> aa
[1] 33 44 55 66 77
> aa[-3] # 3 제거해서 가져옴
[1] 33 44 66 77
> aa[-1:-2] #1과 2번 제거 해서 가져옴
[1] 55 66 77
> aa[2:4]
[1] 44 55 66
> aa[5:6] #없는 값은 NA로 표기
[1] 77 NA
> aa[3]<-100 #값변경
> aa
[1] 33 44 100 66 77
> #새로운 내용을 추가
> aa <-c(aa,200)
> aa
[1] 33 44 100 66 77 200
> #7,8 에 값이 없다(NA : 결측치<측정되지 않는 값>)
> aa[9]<-99
> aa
[1] 33 44 100 66 77 200 NA NA 99
> #실제 aa 에는 추가 되지 않음
> append(aa,1111)
[1] 33 44 100 66 77 200 NA NA 99 1111
> aa
[1] 33 44 100 66 77 200 NA NA 99
> #4번째 다음에 삽입
> append(aa,5454,after=4)
[1] 33 44 100 66 5454 77 200 NA NA 99
> #제일 처음에 값을 삽입
> append(aa,1111,after=0)
[1] 1111 33 44 100 66 77 200 NA NA 99
> z<-c(TRUE,FALSE)
> z
[1] TRUE FALSE
> #백터연산
> c(1,2,3)+c(4,5,6)
[1] 5 7 9
> #각요소에 1을 더함
> c(1,2,3)+1
[1] 2 3 4
> x<-c(1,2,3)
> y<-c(2,3,4)
> x+y
[1] 3 5 7
> #문자 존재시 모두 문자로 변경
> c(1,2,'a')
[1] "1" "2" "a"
> #벡터의 길이를 얻는 함수 length()
> x
[1] 1 2 3
> length(x)
[1] 3
> p<-c(1,2,3)
> names(p)<-c("a","b","c")
> p
a b c
1 2 3 2. 리스트(Lists)
가. 리스트는 이질적 이다.
나. 리스트는 위치로 인덱스된다.
다. 리스트에서 하위 리스트를 추출할 수 있다.
라. 리스트의 원소들은 이름을 가질 수 있다.
> #리스트 : 벡터의 각 원소들이 이름을 갖는다.
> # 각 원소들은 서로 다른 데이터 형식으로 구성 될 수 있다.
> xx<-list("홍길동","201801",20,c("R언어","자바"))
> xx
[[1]]
[1] "홍길동"
[[2]]
[1] "201801"
[[3]]
[1] 20
[[4]]
[1] "R언어" "자바"
> yy<-list("이름"="홍길동","학번"="201801",나이=20,"수강과목"=c("C언어","데이터과학"))
> yy
$이름
[1] "홍길동"
$학번
[1] "201801"
$나이
[1] 20
$수강과목
[1] "C언어" "데이터과학"
> #특정키 값을 보려는 경우
> yy$이름
[1] "홍길동"
> yy$나이
[1] 20
> yy["이름"]
$이름
[1] "홍길동"
> yy["나이"]
$나이
[1] 203. R에서의 자료 형태
| 객체 | 예시 | 모드(mode) |
| 숫자 | 3.1415 | 수치형(numeric) |
| 숫자 벡터 | c(2,3,4,5,6) | 수치형(numeric) |
| 문자열 | "Tom" | 문자형(character) |
| 문자열 벡터 | c("Tom","Yoon","Kim") | 문자형(character) |
| 요인 | factor(c("A","B","C")) | 수치형(numeric) |
| 리스트 | list("Tom","Yoon","Kim") | 리스트(list) |
| 데이터 프레임 | data.frame(x=1:3,y=c("Tom","Yoon","Kim")) | 리스트(list) |
| 함수 | 함수(function) |
4. 데이터 프레임(data frames)
가. 특징
· 데이터 프레임은 강력하고 유연한 구조. SAS의 데이터 셋을 모방해서 만들어짐
· 데이터 프레임의 리스트 원소는 벡터 또는 요인
· 벡터와 요인은 데이터 프레임의 열
· 벡터와 요인들은 동일한 길이
· 데이터 프레임은 표 형태의 데이터 구조이며, 각 열은 서로 다른 데이터 형식을 가질 수 있음
· 열에는 이름이 필요
> #데이터프레임 : 행렬과 유사한 2차원 데이터 구조
> # 행렬과 다른점은 각열이 서로 다른 데이터 형식을 가질수 있다.
> # 데이터 프레임에 들어갈 벡터의 길이는 동일해야 한다.
> x1<-c(11,22,33)
> x2<-c("a","b","c")
> x3<-c(TRUE,FALSE,FALSE)
> x1
[1] 11 22 33
> x2
[1] "a" "b" "c"
> x3
[1] TRUE FALSE FALSE
> df<-data.frame(id=x1, name=x2, marriage=x3)
> df
id name marriage
1 11 a TRUE
2 22 b FALSE
3 33 c FALSE
> df[1]
id
1 11
2 22
3 33
> df["id"]
id
1 11
2 22
3 33
> df[[1]]
[1] 11 22 33
> df[["id"]]
[1] 11 22 335. 그밖의 데이터 구조들
가. 단일 값(Scalars)
· R에서는 원소가 하나인 벡터로 인식/처리
> #단일값(Scalars) > pi [1] 3.141593 > length(pi) [1] 1
나. 행렬(Matrix)
· R에서는 차원을 가진 벡터로 인식
> #Matrix(행렬)
> #matrix() 함수 사용
> #열우선 방식
> #4X1행렬
> m<-matrix(c(1,2,3,4))
> m
[,1]
[1,] 1
[2,] 2
[3,] 3
[4,] 4
> #2X2행렬
> m2<-matrix(c(1,2,3,4),nrow=2)
> m2
[,1] [,2]
[1,] 1 3
[2,] 2 4
> #3X2행렬
> m3<-matrix(c(1,2,3,4,5,6),ncol = 2)
> m3
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> #행우선으로 입력하고자 할 경우에는 byrow=T 설정
> m4<-matrix(c(1,2,3,4,5,6),nrow = 2,byrow = T)
> m4
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
> #컬럼 이름을 지정 colnames()함수
> m5<-matrix(c(1,2,3,4,5,6,7,8,9),nrow=3,byrow=T)
> m5
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
> colnames(m5)<-c('A','B','C')
> m5
A B C
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
> #행추가 함수 rbind()함수
> m5<-rbind(m5,c(10,11,12))
> m5
A B C
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
[4,] 10 11 12
> #열의수가 맞지 않으므로 오류발생 -> 33을제외하고 추가됨
> m5<-rbind(m5,c(11,2,22,33))
Warning message:
In rbind(m5, c(11, 2, 22, 33)) :
number of columns of result is not a multiple of vector length (arg 2)
> m5
A B C
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
[4,] 10 11 12
[5,] 11 2 22
> #열 추가 함수 cbind() 함수 -> 5row이기 때문에 에러-> 11로 나머지 부분추가
> m5<-cbind(m5,c(11,11,11,11))
Warning message:
In cbind(m5, c(11, 11, 11, 11)) :
number of rows of result is not a multiple of vector length (arg 2)
> m5
A B C
[1,] 1 2 3 11
[2,] 4 5 6 11
[3,] 7 8 9 11
[4,] 10 11 12 11
[5,] 11 2 22 11
> m5<-cbind(m5,c(22,22,22,22,22))
> m5
A B C
[1,] 1 2 3 11 22
[2,] 4 5 6 11 22
[3,] 7 8 9 11 22
[4,] 10 11 12 11 22
[5,] 11 2 22 11 22다. 배열(Arrays)
· 행렬에 3차원 또는 n차원까지 확장된 형태
· 주어진 벡터에 더 많은 차원을 부여하여 배열을 생성
> #행렬은 2차원 데이터라면 배열은 다차원 데이터
> #dim -> dimension 차원 3X3행렬
> array(1:9,dim=c(3,3))
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> #2X2 행렬이 3개(3차원)
> array(1:12,dim=c(2,2,3))
, , 1
[,1] [,2]
[1,] 1 3
[2,] 2 4
, , 2
[,1] [,2]
[1,] 5 7
[2,] 6 8
, , 3
[,1] [,2]
[1,] 9 11
[2,] 10 126. 벡터, 리스트, 행렬 다루기
| a <-seq(1,6) | b <-seq(7,9) | a+b | cbind(a,b) | ||||||||
| 1 | 7 | 8 | 1 | 7 | |||||||
| 2 | 8 | 10 | 2 | 8 | |||||||
| 3 | 9 | 11 | 3 | 9 | |||||||
| 4 | 11 | 4 | 7 | ||||||||
| 5 | 13 | 5 | 8 | ||||||||
| 6 | 15 | 6 | 9 | ||||||||
| 기능 | R 코드 | 비고 | ||||
| 벡터에 데이터 추가 | v[length(v)+1]<-newItem | |||||
| 벡터에 데이터 삽입 | append(vec, newvalues, after=n) | |||||
| 요인 생성 | f<-factor(v,levles) | |||||
요인으로 만들기 | comb<-stack(list(v1=v1=,v2=v2,v3=v3)) | |||||
| 백터 내 값 조회 | 벡터[-c[2,4]] | 벡터 내 2,4번째 값을 제외하고 조회 | ||||
| 리스트 | list(숫자, 문자, 함수) | list 함수의 인자로는 숫자, 문자, 함수가 포함 | ||||
| 리스트 생성하기 | L <- list(valuename1 = vec, valuename2 = vec, valuename3 = vec) | |||||
| 리스트 원소 선택 | L[c(n1,n2,n3,···,nk)] : 목록 | |||||
원소 선택 | L$name | |||||
| 리스트에서 원소 제거 | L[["name"]]<-NULL | |||||
리스트에서 제거 | L[is.na(L)]<-NULL | |||||
| 행렬 | e<-matrix(1:20,4,5) | data 대신 숫자를 입력하면 행렬의 값이 동일한 수치값 부여 | ||||
| 차원 | dim(행렬), dim(a) | a 행렬의 차원은 2행 3열 | ||||
| 대각(diagonal) | diag(행렬), diag(b) | b 행렬의 대각선의 값 반환 | ||||
| 전치(transpose) | t(행렬), f(a) | a 행렬의 전치행렬을 반환 | ||||
| 역 | solve(matrix) | |||||
| 행렬의 곱 | 행렬 %*% t(행렬), a %*% t(a) | 행렬의 곱 | ||||
| 행 이름 부여 | rownames(a)<-c("행이름1", "행이름2", "행이름3") | 행의 이름 할당 | ||||
| 열 이름 부여 | colnames(a)<-c("열이름1", "열이름2") | 열의 이름 할당 | ||||
| 행렬의 연산 +,- | f+1, f-1 | 행렬 상수 간 덧셈, 뺼셈 | ||||
| 행렬의 연산 * | f*3 | 행렬 상수 간 곱 | ||||
| 행렬에서 행, 열 선택하기 | vec<-matrix[,3] | |||||
4절 데이터 구조와 데이터 프레임 -2
1. 데이터 프레임
| 기능 | R 코드 | 비고 | |||
| 데이터프레임 | data.frame(벡터,벡터,벡터) | 벡터들로 데이터셋 생성 | |||
| 레코드 생성 | new<-data.frame(a=1,,b=2,c=3,d="a") | 함께 사용 가능 | |||
데이터 프레임 만들기 | dfm<-as.data.frame(list.of.vectors) | ||||
| 데이터셋 행결합 | newdata<-rbind(newdata,new) | 두 데이터프레임을 행으로 결합 | |||
| 데이터셋 열결합 | cbind(newdata,newcol) #newcol=1:150) | 두 데이터프레임을 열로 결합 | |||
| 데이터 프레임 할당 | dtfm <- data.frame( dosage=numeric(N), lab=character(N), responses=numeric(N) ) | ||||
| 데이터 프레임 조회1 | dfrm[dfrm$gender="m"] | 데이터셋 내 성별이 남성만 조회 | |||
| 데이터 프레임 조회2 | dfrm[dfrm$변수1>4 & dfrm$변수2>5, c(변수3, 변수4)] | 데이터셋의 변수1과 변수2의 조건에 만족하는 레코드의 변수3과 변수4만을 조회 | |||
| 데이터 프레임 조회3 | dfrm[grep("문자",dfrm$변수1, ignore.case=T), c("변수2, 변수3")] | 데이터셋의 변수1 내 "문자"가 들어 있는 케이스들의 변수2, 변수3 값을 조회 | |||
| 데이터셋 조회 | subset(dfrm, select=변수, subset=변수>조건) | 데이터셋의 특정 변수의 값이 조건에 맞는 변수셋 조회, subset은 벡터와 리스트에서도 선택 가능 | |||
| 데이터 선택 | lst1[["name1","name2",···,"namek" ]] | ||||
| 데이터 병합 | merge(df1, df2, by="df1과 df2의 공통 열 이름") | 공통변수로 데이터셋 병합 | |||
| 열 네임 조회 | colnames(변수) | 변수의 속성들을 조회 | |||
| 행, 열 선택 | subset(dfm, select=열이름, subset=(조건)) | 열이름에 " " 표시 안함, 조건에 마즌ㄴ 행의 열 자료만 선택 | |||
| 이름으로 열 제거 | subset(dfm, select="열이름") | ||||
| 열 이름 바꾸기 | colnames(dfm)<-newnames | ||||
| NA 있는 행 삭제 | NA_cleaning<-na.omit(dfm) | ||||
두 개 합치기 | 행(rbind_dfm <- rbind(dfm1, dfm2)) | rbind는 열의 개수와 열의 이름이 동일해야 함 | |||
기준으로 합치기 | merge(dfm1, dfm2, by="T_name", all=T) | ||||
2. 자료형 데이터 구조 변환
| 기능 | R 코드 |
내용에 쉽게 접근하기 | detach(dfm) |
| 자료형 변환하기 | as.logical() |
| 데이터 구조 변환하기 | as.vector() |
> #factor type : 범주형 데이터 타입
> #charator type : 문자열을 나타내는 데이터 타입
> #자료형 변환 : as.원하는 자료형
> # as.charater() :문자열 데이터 타입으로 변환
> # as.numeric() : 수치형
> # as.complex() :복수형
> # aslogical() : TRUE,FALSE
> #자료구조 변환
> # as.data.frame()/ as.list() / as.matrix() / as.vector()
> # as.factor
> x<-0:5
> x
[1] 0 1 2 3 4 5
> #str(객체) : 데이터구조, 데이터 타입(자료형), 변수 명, 관찰값 미리보기하는 함수
> str(x)
int [1:6] 0 1 2 3 4 5
> x<-as.character(x)
> str(x)
chr [1:6] "0" "1" "2" "3" "4" "5"
> x<-as.numeric(x)
> x
[1] 0 1 2 3 4 5
> str(x)
num [1:6] 0 1 2 3 4 5
> x<-as.complex(x)
> x
[1] 0+0i 1+0i 2+0i 3+0i 4+0i 5+0i
> str(x)
cplx [1:6] 0+0i 1+0i 2+0i ...
> x<-as.double(x)
> x
[1] 0 1 2 3 4 5
> str(x)
num [1:6] 0 1 2 3 4 5
> #TRUE or FALSE
> # 0 : FALSE , 0을 제외한 나머지 :TRUE
> x<-as.character(x)
> x
[1] "0" "1" "2" "3" "4" "5"
> x<-as.integer(x)
> x
[1] 0 1 2 3 4 5
> str(x)
int [1:6] 0 1 2 3 4 5
> x<-as.logical(x)
> x
[1] FALSE TRUE TRUE TRUE TRUE TRUE
> str(x)
logi [1:6] FALSE TRUE TRUE TRUE TRUE TRUE
> #logical --> integer : TURE 1, FALSE는 0
> x<-as.integer(x)
> x
[1] 0 1 1 1 1 1
> x<-c("a","b","c")
> x<-as.integer(x)
Warning message:
NAs introduced by coercion
> x
[1] NA NA NA
> x<-as.numeric(x)
> x
[1] NA NA NA
> x<-as.logical(x)
> x
[1] NA NA NA
> #자료구조 변환
> x<-0:5
> str(x)
int [1:6] 0 1 2 3 4 5
> x<-as.data.frame(x)
> x
x
1 0
2 1
3 2
4 3
5 4
6 5
> str(x)
'data.frame': 6 obs. of 1 variable:
$ x: int 0 1 2 3 4 5
> #리스트 형태로 변환
> x<-as.list(x)
> x
$x
[1] 0 1 2 3 4 5
> str(x)
List of 1
$ x: int [1:6] 0 1 2 3 4 5
> #matrix로 변환
> x<-0:5
> x<-as.matrix(x)
> x
[,1]
[1,] 0
[2,] 1
[3,] 2
[4,] 3
[5,] 4
[6,] 5
> str(x)
int [1:6, 1] 0 1 2 3 4 5
> BloodType<-c("A","AB","O","O","O","O","O","O","B","B")
> BloodType
[1] "A" "AB" "O" "O" "O" "O" "O" "O" "B" "B"
> BloodType<-factor(BloodType)
> BloodType
[1] A AB O O O O O O B B
Levels: A AB B O
> gender<-c("m","f")
> gender
[1] "m" "f"
> gender<-factor(gender)
> gender
[1] m f
Levels: f m
> nlevels(BloodType)
[1] 4
> nlevels(gender)
[1] 2
> x<-c("M","M","F","M","F")
> x<-factor(x)
> x
[1] M M F M F
Levels: F M
> str(x)
Factor w/ 2 levels "F","M": 2 2 1 2 1
> x<-as.integer(x)
> x
[1] 2 2 1 2 1
> str(x)
int [1:5] 2 2 1 2 1
> x<-as.factor(x)
> x
[1] 2 2 1 2 1
Levels: 1 2
> str(x)
Factor w/ 2 levels "1","2": 2 2 1 2 13. 데이터 구조 변경
| 벡터 → 리스트 | as.list(vec) | 행렬 → 벡터 | as.vector(mat) |
| 벡터 → 행렬 | n X m 행렬 : matrix(vec,n,m) | 행렬 → 리스트 | as.list(mat) |
| 벡터 → 데이터 프레임 | 1행짜리 데이터프레임 : as.data.frame(rbind(vec)) | 행렬 → 데이터 프레임 | as.data.frame(mat) |
| 리스트 → 벡터 | unlist(lst) | 데이터 프레임 → 벡터 | 1행짜리 데이터프레임 : dfm[1,] |
| 리스트 → 행렬 | n X m 행렬 : matrix(lst,n,m) | 데이터 프레임 → 리스트 | as.list(dfm) |
| 리스트 → 데이터 프레임 | 리스트 원소들이 데이터의 행이면 : rbind(obs[[1]],obs[[2]]) | 데이터 프레임 → 행렬 | as.matrix(dfm) |
4. 벡터의 기본 연산
| 기능 | R 코드 | 비 고 |
| 벡터 연산 | 벡터1 ^ 벡터2 | 승수 연산 |
| 함수 적용 | sapply(a,log) | 연산 및 적용 함수를 통해 변수에 적용 |
| 파일 저장1 | write.csv(a,"test.csv") | 파일로 저장 |
| 파일 저장2 | save(a,file="a.Rdata") | 파일로 저장 |
| 파일 읽기 | read.csv("a.csv") | 파일 읽기 |
| 파일 불러오기 | source("a.R") | R파일 불러오기 |
| 데이터 삭제 | rm(list=Is(all=TRUE)) | 모든 변수를 메모리에서 삭제 |
5. 그 외에 간단한 함수
| 기능 | R 코드 | 비 고 |
| 데이터 불러오기 | data(데이터셋) | 데이터셋을 불러드림 |
| 데이터셋 요약 | summary(데이터셋) | 데이터셋 변수 내용을 요약 |
| 데이터셋 조회 | head(데이터셋) | 6개 레코드까지 데이터 조회 |
| 패키지 설치 | install.packages("패키지명") | 패키지를 설치 |
| 패키지 불러오기 | library("패키지 명") | 패키지를 불러들임 |
| 작업 종료 | q() | 작업을 종료 |
| 워킹디렉토리 지정 | setwd("~/") | R데이터, 파일을 로드하거나 저장할 때 워킹 디렉토리를 지정 |
5절 데이터 변형
1. 주요코드
| 기능 | R 코드 | 비 고 | |||
| 요인으로 집단 정의 | f=factor(c("A","B","B","C","A")) | ||||
(벡터의 길이만 같으면 됨) | groups<-unstack(data,frame(v,f)) | 두 함수 모두 벡터로 된 리스트를 반환 | |||
여러집단으로 분할 | median(sp[[1]]) | ||||
함수 적용 | vec<-sapply(l,func) | ||||
| 행렬에 함수 적용 | m<-apply(mat,2,func) | ||||
함수 적용 | 데이터 프레임을 행렬로 변환 후 함수 적용 | ||||
함수적용 | lm(targetVariable~bes.pred) | 4. 타겟변수와 입력변수로 다중회귀분석을 실시한다. | |||
| 집단별 함수 적용 | tapply(vec, factor, func) | 데이터가 집단(factors)에 속해 있을 때 합계/평균 구하기 | |||
| 행집단 함수 적용 | model(dfm, factor, function(df) lm(종속변수~독립변수1+독립변수2+···+독립변수k, data=df)) | ||||
함수적용 | mapply(factor, list1, list2, list3, ···, list k) | ||||
2. 문자열 날짜 다루기
| 기능 | R 코드 | 비 고 |
| 문자열 길이 | nchar("단어") | [주의] length(vec) 문자열의 길이가 아닌 벡터의 길이를 반환 |
| 문자열 연결 | paste(vec, "loves me", collapse=", and") | |
| 하위문자열 추출 | substr("statistics",1,4) | 문자열의 1첫째에서 4자리까지 추출 |
| 구분자로 문자열 추출 | subsplit(문자열, 구분자) | |
| 하위 문자열 대체 | gsub(old, new, string) | |
| 쌍별 조합 | mat<-outer(문자열1, 문자열2, paste, sep="") | |
| 날짜 변환1 | as.Date() | 날짜 객체로 반환 |
| 날짜 변환2 | format(Sys.date(), format=%m%d%y) | |
| 날짜 조회 | format(Sys.Date(), '%Y') | 네지리 숫자의 연도 조회 |
| 날짜 일부 추출 | seq(from=start, to=end, by=1) |
> #유용한 기능들
> #paste 함수
> number<-1:5
> str<-c("aa","bb","cc")
> paste(number,str)
[1] "1 aa" "2 bb" "3 cc" "4 aa" "5 bb"
> paste(number,str,sep="/")
[1] "1/aa" "2/bb" "3/cc" "4/aa" "5/bb"
> x<-data.frame(x1=c("A","B","C","D","E"),x2=c("F","G","H","I","J"))
> x
x1 x2
1 A F
2 B G
3 C H
4 D I
5 E J
> y<-paste(x$x1,x$x2)
> y
[1] "A F" "B G" "C H" "D I" "E J"
> y<-paste(x$x1,x$x2,sep="-")
> y
[1] "A-F" "B-G" "C-H" "D-I" "E-J"
> y<-paste(x$x1,x$x2,sep="")
> y
[1] "AF" "BG" "CH" "DI" "EJ"
> x$x1
[1] A B C D E
Levels: A B C D E
> z<-paste(x$x1,collapse="")
> z
[1] "ABCDE"
> #substr함수 substr(x,start,stop):문자형 벡터 x의 start에서 stop까지잘라오기
> substr("2018-08-08",6,7)
[1] "08"
> substr("2018-08-08",5,9)
[1] "-08-0"
> aa<-c("GOOD","Morning")
> substr(aa,1,2)
[1] "GO" "Mo"
> #nchar : nchar(x) 문자형 벡터 x의 구성요소 개수를 구한다.
> x<-c("Seoul","New York","London","1254")
> x
[1] "Seoul" "New York" "London" "1254"
> nchar(x)
[1] 5 8 6 4
> #strplit함수 : strsplit(x,split=",") :문자형 벡터 x를 split기준으로 나누기
> name<-c("Kim, Gildong","Lee, Minsu","Park, NamGil")
> name_split<-strsplit(name,split=",")
> name_split
[[1]]
[1] "Kim" " Gildong"
[[2]]
[1] "Lee" " Minsu"
[[3]]
[1] "Park" " NamGil"
> lastName<-c(name_split[[1]][1],name_split[[2]][1],name_split[[3]][1])
> lastName
[1] "Kim" "Lee" "Park"
> firstName<-c(name_split[[1]][2],name_split[[2]][2],name_split[[3]][2])
> firstName
[1] " Gildong" " Minsu" " NamGil"
> nameDf<-data.frame(lastName,firstName,name)
> nameDf
lastName firstName name
1 Kim Gildong Kim, Gildong
2 Lee Minsu Lee, Minsu
3 Park NamGil Park, NamGil
> #sub함수 : sub(old,new,x) 문자형 벡터 x에서 처음나오는 old무자를 new 문자를 한번만 바꿈
> z<-c("My name is GilDong.what's your name?")
> sub("name","first name",z)
[1] "My first name is GilDong.what's your name?"
> #gsub(old,new,x) : 문자형 벡터 x에서 모든 old문자를 new 문자로 바꿈
> gsub("name","first name",z)
[1] "My first name is GilDong.what's your first name?"
> sub("My name is GilDong.","",z)
[1] "what's your name?"> # 날짜 데이터
> today<-Sys.Date()
> today
[1] "2020-03-01"
> now<-Sys.time()
> now
[1] "2020-03-01 23:25:58 KST"
> date()
[1] "Sun Mar 1 23:25:59 2020"
> # 문자열 날짜를 Date Type으로 변환하기
> #as.Date(),strptime()
> x1<-"2018-10-10"
> as.Date(x1)
[1] "2018-10-10"
> as.Date(x1,format="%Y-%m-%d")
[1] "2018-10-10"
> as.Date("02/05/2018","%m/%d/%Y")
[1] "2018-02-05"
> as.Date("2018-05-05")
[1] "2018-05-05"
> as.Date("2018년10월10일", "%Y년%m월%d일")
[1] "2018-10-10"
> as.Date("20181010","%Y%m%d")
[1] "2018-10-10"
> format(today , format="%Y년%m월%d일")
[1] "2020년03월01일"
> as.Date("081010","%y%m%d")
[1] "2008-10-10"
> format(Sys.Date(),"%a")
[1] "Sun"
> format(Sys.Date(),"%b")
[1] "Mar"
> format(Sys.Date(),"%Y")
[1] "2020"3장 데이터 마트
1절 데이터 변경 및 요약
1. R reshape를 이용한 데이터 마트 개발
가. 데이터 마트
· DW에서 자신이 원하는 특정 분야의 데이터를 가져왔을 경우
· 데이터웨어하우스와 사용자 사이의 중간층에 위치
나 . 요약변수
· 수집된 정보를 분석에 맞게 종합한 변수
· 총구매 금액, 금액, 횟수, 구매여부 등 데이터 분석을 위해 만드어 지는 변수
· 재활용성이 높음
다. 파생변수
· 특정조건을 만족하거나 특정함수에 의해 값을 만들어 의미를 부여한 변수
· 주관적일 수 있으므로 논리적 타당성을 갖추어 개발
· 세분화, 고객행동 예측, 캠페인 반응 예측
라. reshape 의 활용
· 녹이는 함수 melt(), 모양을 만드는 함수 cast()
· melt() : 원데이터 형태로 만드는 함수 / 쉬운 casting을 위해 적당한 형태로 만들어주는 함수
· melt(data, id=...)
· cast() : 요약형태로 만드는 함수 / 데이터를 원하는 형태로 계산 또는 변형 시켜 주는 함수
· cast(data, fomula=...~variable, fun)
> #reshape
> #install.packages("reshape")
> library(reshape)
> x<-c(1,1,2,2)
> y<-c(1,2,1,2)
> z<-c(40,30,50,25)
> w<-c(70,55,80,45)
> mydata<-data.frame(no=x,day=y,A1=z,A2=w)
> mydata
no day A1 A2
1 1 1 40 70
2 1 2 30 55
3 2 1 50 80
4 2 2 25 45
> md<-melt(mydata,id=c("no","day"))
> #With aggregation
> cast(md,no~variable,mean)
no A1 A2
1 1 35.0 62.5
2 2 37.5 62.5
> cast(md,day~variable,mean)
day A1 A2
1 1 45.0 75
2 2 27.5 50
> cast(md,no~day,mean)
no 1 2
1 1 55 42.5
2 2 65 35.0
> #Without aggregation
> cast(md,no+day~variable)
no day A1 A2
1 1 1 40 70
2 1 2 30 55
3 2 1 50 80
4 2 2 25 45
> cast(md,no+variable~day)
no variable 1 2
1 1 A1 40 30
2 1 A2 70 55
3 2 A1 50 25
4 2 A2 80 45
> cast(md,no~variable+day)
no A1_1 A1_2 A2_1 A2_2
1 1 40 30 70 55
2 2 50 25 80 452. sqldf를 이용한 데이터 분석
· sqldf는 R에서 sql의 명령어를 사용 가능하게 해주는 패키지
· SAS에서의 proc sql와 같은 역할을 하는 패키지
> #sqldf 분석 : SQL문을 활용한 분석 방법
> #select절활용
> #install.packages("sqldf")
> library(sqldf)
> data(iris)
> sqldf("select*from iris")
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
.......
147 6.3 2.5 5.0 1.9 virginica
148 6.5 3.0 5.2 2.0 virginica
149 6.2 3.4 5.4 2.3 virginica
150 5.9 3.0 5.1 1.8 virginica
> sqldf("select*from iris limit 10")
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
> sqldf("select count(1) from iris where Species like 'vi%'")
count(1)
1 503. plyr을 이용한 데이터 분석
· plyr은 apply 함수에 기반해 데이터와 출력변수를 동시에 배열로 치환하여 처리하는 패키지
· split-apply-combine : 데이터를 분리하고 처리한 다음, 다시 결합하는 등 필수적인 데이터 처리 기능을 제공
→ 데이터분할(spllit) → 특정함수적용(apply) → 그 결과를 재조합(combine)
· 데이터 처리 함수 : (입력데이터 형식)(출력데이터 형식)ply
→ 배열, Dataframe, list
· a : 배열, d : 데이터프레임, l : 리스트, m : multi → 5글자
| array | dataframe | list | nothing | |
| array | aaply | adply | alply | a_ply |
| dataframe | daply | ddply | dlply | d_ply |
| list | laply | ldply | llply | l_ply |
| n replicates | raply | rdply | rlply | r_ply |
arguments | maply | mdply | mlply | m_ply |
> # apply함수
> # 벡터, 행렬, 데이터프레임에 임의의 함수를 적용하여 결과르르 얻기 위한 함수
> # apply(x, margin, func)
> sum(1:10)
[1] 55
> d<-matrix(1:9,ncol=3)
> d
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> #margin 행1 / 열2
> apply(d,1,sum)
[1] 12 15 18
> apply(d,2,sum)
[1] 6 15 24
> data(iris)
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
> apply(iris[,1:4],2,sum)
Sepal.Length Sepal.Width Petal.Length Petal.Width
876.5 458.6 563.7 179.9
> #plyr 패키지 사용
> install.packages("plyr")
trying URL 'https://cran.rstudio.com/bin/macosx/el-capitan/contrib/3.6/plyr_1.8.5.tgz'
Content type 'application/x-gzip' length 964410 bytes (941 KB)
==================================================
downloaded 941 KB
The downloaded binary packages are in
/var/folders/ct/0r6cjmv97fj6hbmpmdqffz0h0000gn/T//RtmpKD1Ckw/downloaded_packages
> library(plyr)
> #adply() : 배열(a)을 입력받아 데이터프레임(d)을 출력하는 함수
> # adply(data,margins,func)
> apply(iris[,1:4],1,function(row){print(row)})
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.1 3.5 1.4 0.2
Sepal.Length Sepal.Width Petal.Length Petal.Width
4.9 3.0 1.4 0.2
Sepal.Length Sepal.Width Petal.Length Petal.Width
4.7 3.2 1.3 0.2
Sepal.Length Sepal.Width Petal.Length Petal.Width
4.6 3.1 1.5 0.2
......
Sepal.Length Sepal.Width Petal.Length Petal.Width
4.8 3.0 1.4 0.1
Sepal.Length Sepal.Width Petal.Length Petal.Width
4.3 3.0 1.1 0.1
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.8 4.0 1.2 0.2
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.7 4.4 1.5 0.4
......
Sepal.Length Sepal.Width Petal.Length Petal.Width
6.2 3.4 5.4 2.3
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.9 3.0 5.1 1.8
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17] [,18] [,19]
Sepal.Length 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 4.4 4.9 5.4 4.8 4.8 4.3 5.8 5.7 5.4 5.1 5.7
Sepal.Width 3.5 3.0 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 3.7 3.4 3.0 3.0 4.0 4.4 3.9 3.5 3.8
Petal.Length 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 1.5 1.6 1.4 1.1 1.2 1.5 1.3 1.4 1.7
Petal.Width 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 0.2 0.2 0.1 0.1 0.2 0.4 0.4 0.3 0.3
.......
[,134] [,135] [,136] [,137] [,138] [,139] [,140] [,141] [,142] [,143] [,144] [,145] [,146] [,147] [,148]
Sepal.Length 6.3 6.1 7.7 6.3 6.4 6.0 6.9 6.7 6.9 5.8 6.8 6.7 6.7 6.3 6.5
Sepal.Width 2.8 2.6 3.0 3.4 3.1 3.0 3.1 3.1 3.1 2.7 3.2 3.3 3.0 2.5 3.0
Petal.Length 5.1 5.6 6.1 5.6 5.5 4.8 5.4 5.6 5.1 5.1 5.9 5.7 5.2 5.0 5.2
Petal.Width 1.5 1.4 2.3 2.4 1.8 1.8 2.1 2.4 2.3 1.9 2.3 2.5 2.3 1.9 2.0
[,149] [,150]
Sepal.Length 6.2 5.9
Sepal.Width 3.4 3.0
Petal.Length 5.4 5.1
Petal.Width 2.3 1.8
> #apply -> 1행인경우 벡터출력 / 2차원 행렬형태 / 각행마다 열이 다를경우 list반환
> apply(iris,1,function(row){print(row)})
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
"5.1" "3.5" "1.4" "0.2" "setosa"
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
"4.9" "3.0" "1.4" "0.2" "setosa"
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
"4.7" "3.2" "1.3" "0.2" "setosa"
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
"4.6" "3.1" "1.5" "0.2" "setosa"
......
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
"5.5" "4.2" "1.4" "0.2" "setosa"
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
"4.9" "3.1" "1.5" "0.2" "setosa"
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
"5.0" "3.2" "1.2" "0.2" "setosa" 4. 데이터 테이블
· 데이터 프레임을 대신하여 사용가능
· 기존 data.frame 방식보다 월등히 빠른 속도
· 특정 column을 key 값으로 색인을 지정한 후 데이터를 처리
· 빠른 그루핑과 ordering, 짧은 문장 지원 측변에서 데이터 프레임보다 유용
> # 데이터 테이블
> install.packages("data.table")
trying URL 'https://cran.rstudio.com/bin/macosx/el-capitan/contrib/3.6/data.table_1.12.8.tgz'
Content type 'application/x-gzip' length 2133679 bytes (2.0 MB)
==================================================
downloaded 2.0 MB
The downloaded binary packages are in
/var/folders/ct/0r6cjmv97fj6hbmpmdqffz0h0000gn/T//RtmpKD1Ckw/downloaded_packages
> library(data.table)
data.table 1.12.8 using 8 threads (see ?getDTthreads). Latest news: r-datatable.com
> data(iris)
> iris_table<-as.data.table(iris)
> iris_table
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1: 5.1 3.5 1.4 0.2 setosa
2: 4.9 3.0 1.4 0.2 setosa
3: 4.7 3.2 1.3 0.2 setosa
4: 4.6 3.1 1.5 0.2 setosa
5: 5.0 3.6 1.4 0.2 setosa
---
146: 6.7 3.0 5.2 2.3 virginica
147: 6.3 2.5 5.0 1.9 virginica
148: 6.5 3.0 5.2 2.0 virginica
149: 6.2 3.4 5.4 2.3 virginica
150: 5.9 3.0 5.1 1.8 virginica
> #데이터 테이블은 데이터 프레임과 동일하게 취급된다.
> x<-data.table(x=c(1,2,3),y=c("a","b","c"))
> x
x y
1: 1 a
2: 2 b
3: 3 c
> tables() # 만들어진 데이터테이블 목록을 확인할 대 사용한다.
NAME NROW NCOL MB COLS KEY
1: iris_table 150 5 0 Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,Species
2: x 3 2 0 x,y
Total: 0MB
> DT<-as.data.table(iris)
> #데이터 테이블 접근[행,표현식,옵션]
> DT[1,]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1: 5.1 3.5 1.4 0.2 setosa
> DT[DT$Species =="setosa",]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1: 5.1 3.5 1.4 0.2 setosa
2: 4.9 3.0 1.4 0.2 setosa
3: 4.7 3.2 1.3 0.2 setosa
4: 4.6 3.1 1.5 0.2 setosa
5: 5.0 3.6 1.4 0.2 setosa
6: 5.4 3.9 1.7 0.4 setosa
7: 4.6 3.4 1.4 0.3 setosa
8: 5.0 3.4 1.5 0.2 setosa
9: 4.4 2.9 1.4 0.2 setosa
........
33: 5.2 4.1 1.5 0.1 setosa
34: 5.5 4.2 1.4 0.2 setosa
35: 4.9 3.1 1.5 0.2 setosa
36: 5.0 3.2 1.2 0.2 setosa
37: 5.5 3.5 1.3 0.2 setosa
38: 4.9 3.6 1.4 0.1 setosa
39: 4.4 3.0 1.3 0.2 setosa
40: 5.1 3.4 1.5 0.2 setosa
41: 5.0 3.5 1.3 0.3 setosa
42: 4.5 2.3 1.3 0.3 setosa
43: 4.4 3.2 1.3 0.2 setosa
44: 5.0 3.5 1.6 0.6 setosa
45: 5.1 3.8 1.9 0.4 setosa
46: 4.8 3.0 1.4 0.3 setosa
47: 5.1 3.8 1.6 0.2 setosa
48: 4.6 3.2 1.4 0.2 setosa
49: 5.3 3.7 1.5 0.2 setosa
50: 5.0 3.3 1.4 0.2 setosa
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
> DT[1,Sepal.Length]
[1] 5.1
> DT[1,"Sepal.Length"]
Sepal.Length
1: 5.1
> DT[1,list(Sepal.Length,Species)]
Sepal.Length Species
1: 5.1 setosa
> DT[,mean(Sepal.Length)]
[1] 5.843333
> DT[,mean(Sepal.Length-Sepal.Width)]
[1] 2.786
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
> iris[1,1]
[1] 5.1
> DT[1,1]
Sepal.Length
1: 5.1
> DT[,mean(Sepal.Length),by="Species"]
Species V1
1: setosa 5.006
2: versicolor 5.936
3: virginica 6.588
> DT2<-data.table(x=c("b","b","b","a","a"),v=rnorm(5))#정규분포도도rnorm
> DT2
x v
1: b -0.08776191
2: b 1.21173273
3: b 0.17439265
4: a 0.44670241
5: a 0.66576008
> tables()
NAME NROW NCOL MB COLS KEY
1: DT 150 5 0 Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,Species
2: DT2 5 2 0 x,v
3: iris_table 150 5 0 Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,Species
4: x 3 2 0 x,y
Total: 0MB
> setkey(DT2, x) #setkey(데이터테이블,정렬할 컬럼)
> DT2
x v
1: a 0.44670241
2: a 0.66576008
3: b -0.08776191
4: b 1.21173273
5: b 0.17439265
> tables()
NAME NROW NCOL MB COLS KEY
1: DT 150 5 0 Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,Species
2: DT2 5 2 0 x,v x
3: iris_table 150 5 0 Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,Species
4: x 3 2 0 x,y
Total: 0MB
> DT2["a"]
x v
1: a 0.4467024
2: a 0.6657601
> DT2["b"]
x v
1: b -0.08776191
2: b 1.21173273
3: b 0.17439265
> DT2["b",mult="first"]
x v
1: b -0.08776191
> DT2["b",mult="last"]
x v
1: b 0.17439272절 데이터 가공
1. Data Exploration
나. 종류
1) head(데이터셋), tail(데이터셋)
· 시작 또는 마지막 6개 record만 조회
2) summary(데이터셋)
· summary() 주어진 벡터에 대한 각 사분위 수 최소값, 최대값, 중앙값, 평균
· Min : 최소값, 1st Qu : 1사분위수, Median : 중위수, Mean : 평균, 3st Qu : 3사분위수, Max : 최댓값
3. 변수 구간화
나. 구간화 방법
1)binning
· 신용 평가 모형의 개발에서 자주 활용
2)의사결정나무
· 분리 기준값으로 연속형 변수를 구간화
3절 기초 분석 및 데이터 관리
1. 데이터 EDA(탐색적 자료 분석)
· summary()를 이용하여 데이터의 기초 통계량을 확인
2. 결측값 인식
· 결측값은 NA, 99999999, ' '(공백), Unkown, Not Answer 등으로 표현되는 것으로 결측값을 처리하기 위해서 시간을 많이 사용하는 것은 비효율적
· 결측값 자체의 의미가 있는 경우
→ 쇼핑몰 가입자 중 특정 거래 자체가 존재하지 않는 경우
→ 인구통계학적 데이터(demographic data)에서 아주 부자이거나 아주 가난한 경우 자신의 정보를 잘 채워 넣지 않기 때문에 가입자의 특성을 유추하여 활용
· 결측값 처리는 전체 작업속도에 많은 영향을 줌
· NAN은 Not A Number로 결측값이 아니라 숫자형 데이터 인데 숫자 이외의 문자가 오는경우
· 이상값 검색 → 꼭 제거하는 것은 아님. 분석의 목적/종류에 따라 적절히 변환/제거
> #결측값 > x<-c(1,2,3,NA) > x [1] 1 2 3 NA > mean(x) [1] NA > #na.rm : NA를 Remove 할까요? TRUE, FALSE > #결측값을 제거해버리고 3개로 평균을 계산함 > mean(x,na.rm=TRUE) [1] 2
3. 결측값 처리방법
가. 단순 대치법(Single Imputation)
1) completes analysis
· 결측값이 존재하는 레코드를 삭제
2) 평균대치법(Mean Implutation)
· 관측 또는 실험을 통해 얻어진 데이터의 평균으로 대치한다.
· 비조건부 평균 대치법 : 관측데이터의 평균으로 대치
· 조건부 평균대치법(regression imputation) : 회귀분석을 활용한 대치법(결측값이 있는 변수를 종속변수로 하는 회귀분석 활용)
3) 단순확률 대치법(Single Stochastic Imputation)
· 평균대치법에서 추정량 표준 오차의 과소 추정문제를 보완하고자 고안된 방법(Hot-deck방법, nearest neighbor방법)
나. 다중 대치법(Multiple Imputation)
· 단순대치법을 한번하지 않고 m번의 대치를 통해 m개의 가상적 완전 자료를 만드는 방법
· 1단계 : 대치(imputation step), 2단계 : 분석(analysis step), 3단계 : 결합(combination step)
4. R에서 결측값 처리
가. 관련함수
| 함수 | 내용 |
| complete.cases() | 데이터내 레코드에 결측값이 있으면, FALSE, 없으면 TRUE로 반환 |
| is.na() | 결측값을 NA로 인식하여 결측값이 있으면 TRUE, 없으면 FALSE로 반환 |
5. 이상값(Outlier) 인식과 처리
가. 이상값이란?
· 회귀모형으로 잘 예측되지 않는 관측치(즉, 아주 큰 양수/음수의 residual)
· 표준잔차에서 2배이상 크거나 2배이상 작은 관측치
· 의도하지 않게 잘못 입력한 경우(Bad Data)
· 의도하지 않게 입력되었으나 분석 목적에 부합되지 않아 제거해야하는 경우(Bad Data)
· Bad Data 삭제하는 것이 바람직
· 의도하지 않은 현상이지만 분석에 포함해야 하는 경우
· 의도된 이상값(fraud, 불량)인 경우
· 회귀모형으로 잘 예측되지 않는 관측치
1) 큰 지레점(high leverage point)
· 비정상적인 예측변수의 값에 의한 관측치. 즉, 예측 변수 측의 이상치로 볼 수 있음.
· 종속변수의 값은 관측치의 영향력을 계산하는데 사용하지 않음
· hat = 인수갯수/n (hat : 통계량, hat값의 2~3배 이상의 관측치 / 인수 갯수 : 절편 포함)
ex) y=b+ax (인수갯수 : 2)
2) 영향 관측치(influential observation)
· 통계 모형 계수 결정에 불균형한 영향을 미치는 관측치로 cook's distance라는 통계치로 확인할 수 있음
· D statistics(cook's distance) = 4/(n-k-1) (n : 샘플갯수,k : 예측변수, 독립변수, 설명변수 수)
나. 이상값 인식 방법
1) ESD(Extreme Studentized Deviation)
· 평균으로부터 3 표준편차 떨어진 값(각 0.15%) (평균 - 3표준편차 ~ 평균 + 3표준편차)
2) 기하평균-2.5 X 표준편차 < data < 기하평균 + 2.5 X 표준편차
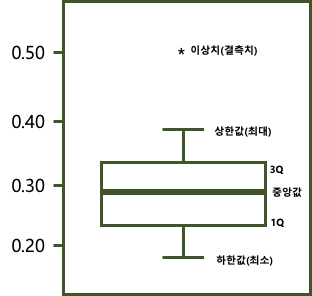
3) 사분위수 이용하여 제거(사분위수의 Q1, Q3로 부터 2.51QR이상 떨어져 있는 데이터)
· 이상값 정의 : Q1-1.5(Q3-Q1) < data < Q3+1.5(Q3-Q1)를 벗어나는 데이터
다. 극단값 절단(trimming) 방법
1) 기하평균을 이용한 제거
· geo_mean
2) 하단, 상단 % 이용한 제거
· 10% 절단(상하위 5%에 해당되는 데이터 제거)
라. 극단값 조정(winsorizing) 방법
'ADSP' 카테고리의 다른 글
| PART 03 데이터 분석 - 3 (0) | 2020.03.14 |
|---|---|
| PART 03 데이터 분석 - 2 (0) | 2020.03.06 |
| PART 02. 데이터 분석 기획 (0) | 2020.02.23 |
| PART 01. 데이터 이해 (0) | 2020.02.22 |
| [ADSP] R Studio설치 (0) | 2020.01.21 |



